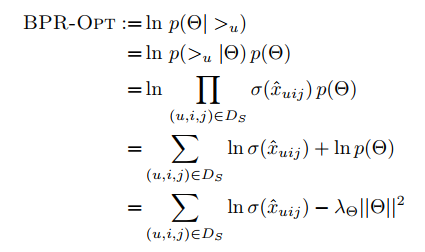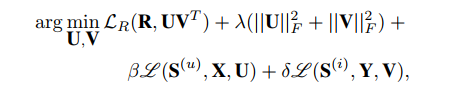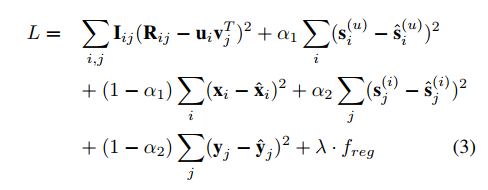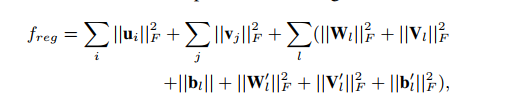摘要
物品推荐是在物品集合中预测出个性排序列表的一项任务。从隐式反馈中做个性推荐的方法有很多,比如矩阵分解、k近邻等。虽然这些方法都可用于物品个性化推荐,但是他们都没有直接对排序做优化。这篇论文提出了一种通用的应用于个性化排序的优化方法,这种方法称为BPR-OPT。BPR-OPT是对问题做贝叶斯理论分析后,通过最大化后验概率进行排序。针对BPR-OPT模型,论文提出了一种基于SGD的自采样学习算法。
BPR是一种基于矩阵分解的排序算法,与funkSVD之类的算法比,它不是做全局的评分优化,而是针对每一个用户自己的商品喜好分贝做排序优化。因此在迭代优化的思路上完全不同。同时对于训练集的要求也是不一样的,funkSVD只需要用户物品对应评分数据二元组做训练集,而BPR则需要用户对商品的喜好排序三元组做训练集。
在实际产品中,BPR之类的推荐排序在海量数据中选择极少量数据做推荐的时候有优势,因此在某宝某东等大厂中应用也很广泛。
BPR模型
模型介绍
BPR基于矩阵分解模型,给定用户集U和物品集I,以及稀疏的用户-物品交互矩阵X,通过矩阵分解得到低维的用户矩阵W(|U|k)和物品矩阵H(|I|k)。通过优化算法使得X^尽可能与实际的X相近。
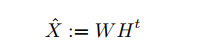
用户u对物品i的喜好程度通过用户向量wu和物品向量hi计算得到。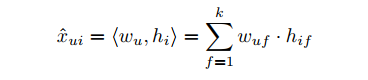
BPR优化算法
BPR算法中,三元组<u,i,j>表示对于用户u来说,物品i的排序比j靠前,>u表示用户u对应的所有物品的全序关系。BPR基于最大化估计P(W,H|>u)来求解模型参数W,H。
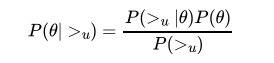
论文做了两个假设:
- 每个用户之间的偏好行为相互独立,即用户u在商品i和j之间的偏好和其他用户无关。
- 同一用户对不同物品的偏序相互独立,也就是用户u在商品i和j之间的偏好和其他的商品无关。
基于假设一,有:
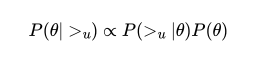
那么现在求解分成两部分。
- 第一部分
基于假设二,有:

P(i >u j|θ)可以通过以下式子求解:
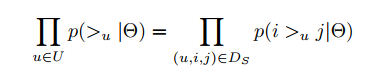
σ(x)是sigmoid函数,σ里面的项我们可以理解为用户u对i和j偏好程度的差异,那么最简单的计算方法就是差值。
- 第二部分
论文使用贝叶斯假设,假设该概率分布符合正态分布。
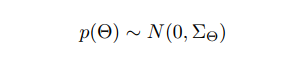
基于以上推导,最终的最大后验估计函数为: