背景
这篇论文是携程的研究人员发表的。论文指出,虽然已经有不少协同过滤方法应用了辅助信息来缓解冷启动和数据稀疏的问题,但是由于评分矩阵和辅助信息的稀疏性,导致学习到的潜在因子不是非常有效。为了解决这个问题,论文提出一种混合深度协同过滤模型,同时利用评分矩阵和辅助信息来学习潜在因子,最后使用矩阵分解还原评分信息。
模型
附加信息栈式去噪自编码器
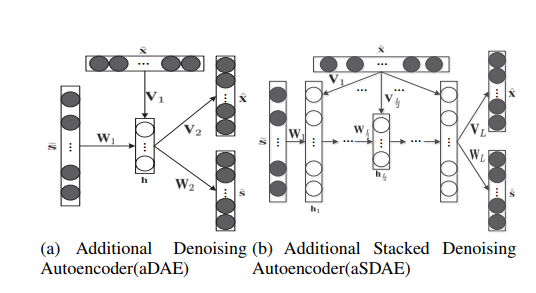
- 附加信息去噪自编码器(aDAE)
mDAE的模型结构如上图(a)所示,可以看成是改进的三层自编码器结构,其中:输入层是评分向量的损坏版本,也就是在原始的评分向量中加入了噪声,一般来说,有两种加入噪声的做法:加性各向同性高斯噪声或二进制掩蔽噪声。添加噪声的目的是为了学习到更具鲁棒性、更有效的特征表示。隐藏层的输入包含两个两方面,一部分来自输入层,另一部分来自辅助信息层,辅助信息层的输入是编码并做加入噪声后的辅助信息向量。输出层包含两个部分,分别是重构之后的评分向量以及辅助信息向量。编码解码过程如下所示,h其实就可以看作是用户或者物品的潜在因子。
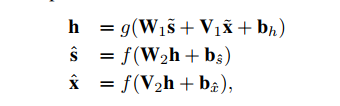
- 附加信息栈式去噪自编码器(aSDAE)
理解了上面的模型,那么aSDAE也就容易理解了。如上图(b)所示,可以看到aSDAE是在普通的aDAE的结构上,将多个aDAE堆叠起来构成的。这样做的原因主要是多层的神经网络可以在隐藏层产生更加丰富的表示,从而提升性能。
混合协同过滤模型
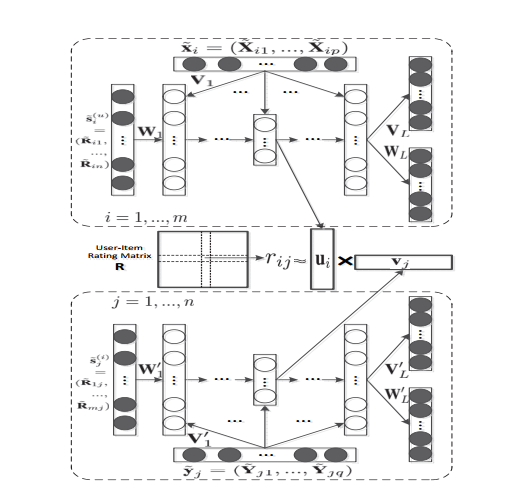
模型由三个组件构成:上面和下面分别是aSDAE模型,用于抽取用户和物品的潜在因子;中间是将利用aSDAE生成的用户和物品的潜在因子生成评分矩阵。
损失函数
模型根据评分矩阵、用户和物品的评分向量、用户和物品的辅助信息来学习用户和物品的潜在因子表示,目标函数如下:
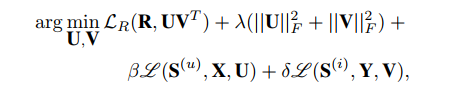
论文为了简单起见,将aSDAE的代价参数置为1,得到以下目标函数:
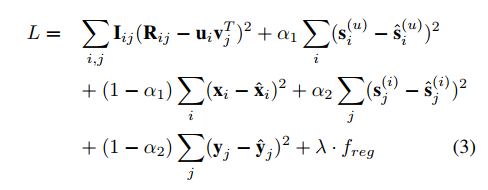
其中,I是指示矩阵,指示R中的非空矩阵元素,也就是说如果矩阵中的元素不为零,I 不等于 0;否则I 等于 0。a为代价参数,f是正则项用于避免过拟合。
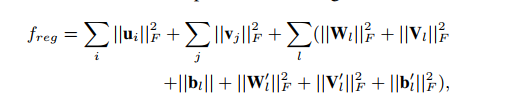
论文使用SGD最优化目标函数。
实验
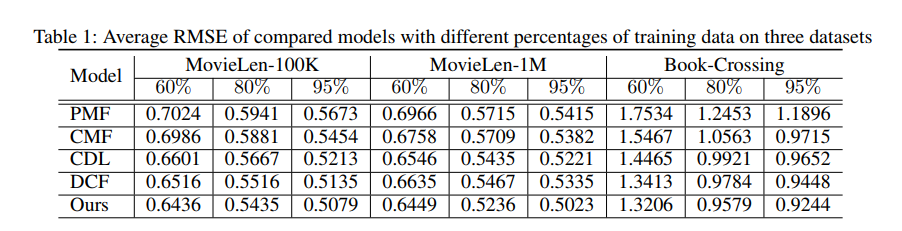
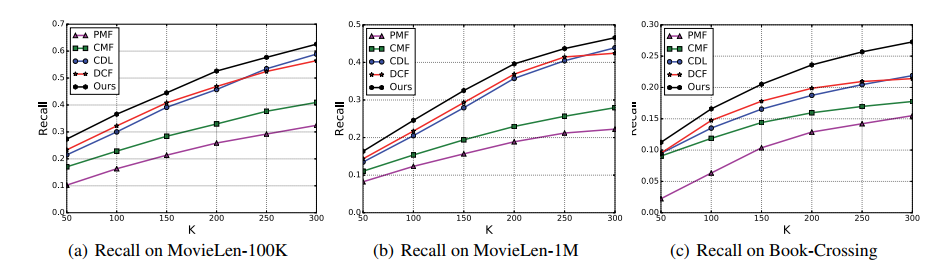
实验部分,作者使用movielens数据集(100k和1M)和Book-Crossing数据集,用RMSE和recall@K作为评价指标,baselines:PMF,CMF,CDL,DCF。实验结果如下: